Waiting for the Miracle — Functional Programming in PHP (Part 7)

Many people consider Functional Programming a miracle, that will save software from being buggy. That high expectation is doomed to fail. Nevertheless FP has its merits, and if you learn them, you will seek and maybe recognize the same merits in other paradigms as well. Those merits focus on ruling complexity, and the demand for that is older than punch cards.
In the present (and hopefully last) article in the series of Functional Programming in PHP we will walk through how FP copes with complexity. We will do so developing a small web framework that resembles Ruby’s Sinatra, so let’s call it Cohen, as a tribute to the great singer, who sang us about the waiting for the miracle…
Expectation Management
Often how we judge an outcome depends on what kind of expectations we set before. Therefore it’s key to manage expectations early — says the guy who’s writing the last part of a series. Nevertheless I attempt to summarize here shortly what target I’m trying to achieve at the end of this article.
We will write a small experimental framework, that makes it possible to expose HTTP endpoints as easily as possible. I don’t intend to write the communication layer. It’s already written, and it’s great, non-blocking, perfect for our purposes. Almost perfect, that is, because we also want a purely functional framework, while React is not quite that. This is however even better, because like this, we can demonstrate how we can wrap unsafe code into safe one, how our functions remain pure, while also interact with the external world, and definitely trigger some side effects at some point.
Also this is not a complete framework. I don’t care many utility features for now. All that I care is that I should be able to define an API as easy as the following snippet:
startServer(
requestHandler(
get('/', ok(SERVER_BOOT_MESSAGE)),
get('/path/sub', ok("Sub\n")),
get('/path/something/:what', ok(fn($request, $matches) => 'You are at: ' . $matches[':what'] . "\n")),
post('/post/:where', ok(function($request, $matches) {
return "Posted here: {$matches[':where']}\nparsedBody: " . var_export(f::prop('parsedBody', $request), true) . "\n";
}))
), '127.0.0.1:8080'
)->runIO();The API
As we can see it has a declarative syntax, and every function here (except runIO) is pure and referential transparent. Anyone who knows how HTTP works can guess what this snippet does. It’s almost like a Domain Specific Language, although it’s vanilla PHP from beginning to end.
Our startServer function accepts two parameters. One is like a request handler and the other is the host and port of the server to listen on, presented here as raw string.
The requestHandler is not actually handling a request. We didn’t say any word about what to do when a request comes in, nor we have to. It will just return a function that is capable of handling request according to the parameters we passed or specification we declared embedded into something which is actually a function call. How he does that? — that’s the private attribute of the implementation. All we need to know is that we can declare the request we support here. It can be GET, it can be POST, or the regular HTTP verbs (which I don’t implement them all here). And such verbs are defined with a path and a response. That’s it.
It can be ok for HTTP 200 response, or not_found for 404, anything we define. They actually expand to a more generic response function that expects a status code, an array of headers, and a renderer, that can be a template processor or as simple as a string to directly output.
Behind the Scenes
In the above snippet (which is essentially all what my application does), we can see that the request handler list is structured in a way that it’s divided into defining a request we’re trying to catch, and a response to be given to that request.
We can also see that the ok function accepts either a string or a function parameter. The function passed like this, itself is expected to accept two parameters, something containing data about the request, and an array of matches. This latter comes from the path we provided in advance. So somewhere behind the curtains a function will process that path, and extract all the wildcards and their corresponding values from the actual path. Such placeholders are useful when we want to collect data from the URL, and want to prepare our application to be flexible to respond them all, while not polluting the URL with queries: /path/something?what=value_of_what.
The only function here that directly comes from the Functional API is the prop function, which is very easy, just returns the named property of an ‘object’. Why don’t we just use something like $obj->$prop? Because that’s not functional. We cannot compose or pipe it with other functions. We can only use it as a value. If everything can be an object in an Object Oriented language, similarly everything can be a function in a Functional language, and this is the preferred way of designing solutions there.
Of course there are other things happening hidden in the background, but these are the ones that we can see right now only by having a glance at the usage example.
Generalization vs Specialization
Whenever we see that the only difference between two functions is the data, we can abstract that out to a more generic function. This can be applied reversely as well: whenever we keep on passing the same data over and over again, we can wrap that function into a more specialized function that spares us from passing that data all the times.
We applied that twice here so far: we have the handle functions with three arguments: a HTTP verb, a path and a handler, and from that we created the convenience functions get and post, and we have the response function described above, and wrapped into ok (and probably not_found, etc. later).
Which direction you take, proceeding from one abstract to many specialized functions or from many specialized to one abstract, it doesn’t actually matter, the only important thing to notice is the pattern, so that you can recognize the opportunity to simplify things.
The good software engineering practice is to break things down from generic ideas to detailed implementations, but it’s an iterative process, and often we need to go back and factor the repeating parts out, therefore we need both approaches.
Matchmaking
We need to be able to tell in advance whether we want to handle a request or not. This is to avoid awkward situations when we receive a request from subpar fellows. In our case we have the method and the path to decide. We will do the following:
- Split the path declared by the handler into steps.
- Split the path coming from the potential request into steps.
- Check whether the method and the number of steps in each match, and that they can be assigned to each other.
For example post('/post/:where'... from above will match, if we receive a POST request on the path ‘/post/something’, where ‘something’ can be assigned to the declared step ‘:where’, because it’s a wildcard designed to capture the actual value at that position.
A simplified sketch of the matchmaker function:
function getMatches($matchTuple, $request): array {
return f::assign(
pathToSteps($matchTuple[1]),
pathToSteps(path($request)),
fn($keys, $values) => match (...) {
true => array_combine($keys, $values),
false => []
}
);
}The function assign just binds all but the last parameter to the scope of the function given as last parameter. This is useful if we want to prepare some data in advance.
The preparation and checking can be delegated, which keeps our functions simple and focused on one responsibility. Similarly the delegated function will be trivial and easily testable.
Note the standardized output: array, which is directly usable even if it’s empty.
Handling Requests

At this point we shouldn’t forget our expectation. We don’t actually handling requests just yet. Accordingly, our function should just compose other functions that are prepared to handle requests once we have them.
It may be helpful to summarize the tasks we’re trying to carry out at this phase:
- identifying the request as something we can/will handle
- creating a function that calls the handler with the processed data in case there’s a match
That’s all. Our handle will return a function. Clear and safe. It’s even wrapped with curry to make sure to expect more in case they are not yet available. Do you remember us passing any requests around in the initial code snippet? Neither I do. There’s no request yet. That can come only when we started the server and listening. Our requestHandler just accepts request matchers and returns a function that accepts a request, and returns whatever the underlying network framework (React) expects us to return (Promise).
While a promise is technically a Task, we cannot use it directly, because it doesn’t implement the functional interfaces that would make it a proper container.
There can be any number of request matchers. It’s up to the user of the framework to decide. So we can’t tell in advance, but we also don’t care, because we can use array_reduce to find one that actually matches. We can also provide an initial value, that we can use as default response — most likely 404 Not Found.
The Backbone
With Functional Programming we can easily sketch everything we plan to do just like we would do with Structured Programming.
function startServer(callable $requestHandler, $host = '0.0.0.0:0'): IO {
return f::pipe(
serverLoopIO($requestHandler),
f::chain(socketIO($host)),
f::map(listen()),
f::map(startLoop())
)(loopIO());
}Important to note that the functions we see here don’t actually perform the task their name might be associated with. They instead either prepare instances or return a function that will perform the task as soon as all the prerequisites are fulfilled for them, and they are explicitly triggered to do so.
The first of such a function is loopIO which wraps a fresh instance of a React LoopInterface into an IO container. IO is better for our purposes because we can postpone the instantiation until we’re ready to pull the trigger.
serverLoopIO prepares a function that requires two parameters: a request handler and a container holding the loop. Then because that’s a Functor (something mappable), it will map — that is: mutate the embedded loop into something else, in our case an object containing all the instances React requires to start the server. We’re only interested in the loop and the server, we quickly instantiate it on-the-fly.
function serverLoopIO(...$args): callable {
return f::curry(fn($requestHandler) => f::map(fn($loop) => IO::of(serverInstances($loop, new Server($loop, $requestHandler)))))(...$args);
}Now we have everything carefully wrapped in an IO container, but we need to combine it with another container holding the host. The host is either given already, or we have an error, so optimally wrapped in an Either container. Luckily all these containers are Applicatives as well, so we can combine them with liftA2, and the result will still be wrapped in a container. But because it was already in a container, an IO, we need to get rid of the superfluous wrapping, and keep just one with chain.
At this point we have the server instances object wrapped in an IO container. We can easily ask it to listen by mapping a function on it which will accept the server instances object, extract the socket from it, and maps another function on it, which will just call listen, as if it was in $server->listen($socket).
function listen(...$args) {
return f::curry(function($serverInstances) {
socket($serverInstances)
->map(fn($socket) =>
server($serverInstances)->listen($socket));
return $serverInstances;
})(...$args);
}It might seem so that we carelessly return the server instances object at this point, but remember that we’re still inside of the IO container, we’re just mapped, and the IO::map method always return IO, so we never leave the container:
public function map(callable $fn): IO {
return new IO(FunctionalAPI::compose($fn, $this->fun));
}Finally we will map another function on the container that calls run on the loop, and that’s it. Still nothing happened. All that we did was just passing functions around and composing, mapping, wrapping them to our needs.
What pipe returns after all these is just an IO container. That’s why we called runIO on it at the beginning. That’s our trigger. That will unfold everything that is prepared within the container.
Mapping the Terminology
Notice that so far we worked with three kinds of entities in Functional Programming:
- Functions — like
prop,assign,maybe - Containers — like Maybe, IO, Task
- Interfaces — like Functor, Applicative, Monad
The two latter are rather inaccurate. They represent the concept and implementation respectively, but they are called differently in other purely functional languages like Haskell, so a mapping might be useful.
Containers are called Types in Haskell, but it’s easier to think about them as ‘boxes’ that wrap some values for safe handling.
Interfaces that we defined sparingly (Functor, Applicative), but implemented thoroughly in our containers (Either, IO, Left, Maybe, Right, Task), are called Type Classes in Haskell. Nevertheless they only define constraints on Types, so it’s safe to consider them as interfaces in a multi-paradigm language like PHP.
It would be problematic to adopt the terminology used in Haskell, because many of the adopting languages, like Java, PHP, or even JavaScript, already have types of a different kind.
These languages often enter the FP domain in the above order, hence next adding containers to the already existing concept of functions. We can see Future, Promise or even Optional (Maybe) to pop up frequently.
The problem is that they lack the constraints. They implement no functional interfaces that could be considered as Type Classes, and therefore we cannot rely on them much to do purely functional programming — which is a shame.
Nevertheless, I believe, nothing prevents these languages to implement those constraints later, and open the gate towards a much wider possibilities to use them in a purely functional way. Until then, we can implement them on our own which is the path often taken in the form of third-party libraries like the one we’re kind of also writing.
The Balance
We managed not only to wrap React into purely functional containers and separated safe code from unsafe code that will have side effects, but also implemented a configuration parsing matchmaker which glues the request with the response. In the framework code we had only one class — a thin one — to pass the instances around that React needs. It even lacks any methods:
class ServerInstances {
public function __construct(
public \React\EventLoop\LoopInterface $loop,
public \React\Http\Server $server,
public \React\Socket\Server | null $socket = null
) {}
}The rest are all self-containing pure functions, of which the longest one expands to just 12 lines of code!
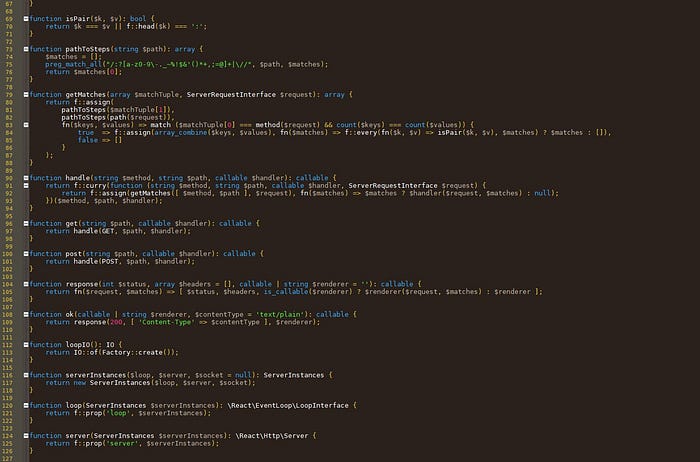
The whole file is only 200 lines long. One might have a Vim configuration longer than that! It’s fully testable and reusable, however I didn’t bother writing test at this point — never do this at home! More sophisticated FP oriented languages, like Elixir, let your documentation be your tests, so you don’t need to repeat yourself.
I admit, on the other hand, that this squeezing, manipulating, wrapping, folding, unwrapping of functions can cause nausea, and recognizing the patterns or possible patterns requires practice and it’s nowhere near trivial. This brings us back to our initial point, that even Functional Programming won’t grant us salvation, and it’s not a miracle we’ve been waiting for. However I wouldn’t dismiss it just by that, because we can see even from this small example, that it has several huge benefits comparing to other paradigms:
- it’s expressive
- it supports developing Domain Specific Languages
- it’s concise
- it’s clean
- it encourages software engineering best practices
- it keeps side effects under control
- it propagates immutability to eliminate classes of bugs
- it’s easily testable
Just by learning this approach, we can develop good habits of programming, and we can be more vigilant on the problems that threaten us regardless of which paradigm we actually pick. Soon we will realize that all of them offers tools to cope with complexity, and they are useful just as long as the tools themselves don’t become too complex. Furthermore, nobody gets better in programming by not knowing about stuff, so learning new or old approaches is never a bad idea. The more you know, the more reliably you can decide which tool to take to solve a certain problem effectively.

Outro
Thank you for following along with this short journey in the domain of Functional Programming and took the experiments with me using PHP and its latest features in version 8. If you’d like to play around with the code and try out the examples yourself, it’s all publicly available on Github filled with extras not covered here.
From now on, I don’t plan to cling on PHP any longer, but from time to time I might pull out an interesting topic, and implement it in PHP if that illustrates the example well.
Beyond that, stay tuned for my other articles here on medium about programming, software engineering, and the philosophy emerges from therein, as well as the fun it can provide for those who keep their eyes open enough.
Cheers!
